 Project Duck News
Project Duck News
![[Tech] Rapidly developing and deploying to Duck's test server](/content/images/size/w2000/2020/11/Untitled-1-1.jpg)
Another techblog! It's been a while, and I recently made some big changes on how we deploy changes to our test server while working on patches.
I'll be covering a bit of background and history, go through the various improvements and stages that I've made over the roughly 1 year that we've had a test server, and what we have now.
Buckle up, we're going fast.
The good ol' days
Literally me and Altair had remote desktop access to the test server and we'd just yeet files onto it whenever people had stuff. This was okay at first (because we were the only ones really doing dev work), but as we expanded the team this would bottleneck on us a lot. We also had no easy way to revert to a last known good state (LKG) so if test server broke we'd have to re-copy files from production, which took forever.
We constantly had issues where test and prod would fall out of sync as well, so we'd make a change based on test server and random things would just break, or changes we made that were good on test would totally fuck up production (and we'd scramble and make an emergency patch).
Hello Git
I introduced using git on the production server to help us track changes and be able to rollback patches whenever shit hit the fan, so naturally I set it up on test as well. We had a script (named "time machine" since it was the easiest way to explain it to the rest of the team who at the time were not familiar with it) that was to be run every time prod was patched (with a little form asking for some details), and that script was adapted for test server to automatically create and switch to a test branch.
Since that git repository contained all the (server side) files, this solved the problems around being out of sync with prod and being able to revert test to match prod whenever we needed to start over (either due to a messed up test patch or because we'd just released).
At this point we gave Joorji and Kozima remote desktop access as well, since they had proven themselves to be very capable and trustworthy developers. We still all were copy-pasting files from our local work folders (or sending random files over Discord to whoever happened to be working the most on the server) so we still had issues related to multiple people working on the same file(s) at the same time, accidental rollbacks, and being bottlenecked on who's able to be on the server.
This went on for months (and its kinda mind boggling that we were shipping patches weekly or more doing this).
DNT-Track
A long time ago I had considered properly leveraging git to track changes to files - almost all of DN's interesting files are in some binary format, which makes them opaque to git, which means we can't leverage git's powerful features to streamline our work and allow true collaboration.
One HUGE pain point were DNTs - Dragon Nest Tables. These tables are essentially Excel spreadsheets for the game and control a vast majority of the game's information. The problem is that these tables tend to be very big and broad - there's one table for all cleric skills, for instance, so if one person was working on Guardian skills and another on Inquisitor, you couldn't do your work at the same time.
Since the data is tabular, it would make sense to represent it in some textual format so that we can edit it more easily. The "state of the art" for DNT editing at the time consisted of:
- Using a very old DNT editor tool, which was a glorified table view with editable fields that loved to crash randomly
- Using DNTEdit, which was a JSON-based edit-command driven tool that I had written (you author a JSON file that describes your changes (e.g. "edit row 126, column "_Damage", value 281"), and the tool reads it in and executes them)
- Dumping the tables to SQL Server, edit using whatever SQL tool you liked, and reimporting them
Of these, only DNTEdit had any reasonable possibility of being usable in git, but because it described deltas, it wasn't really suitable.
And so I decided to create tools to export and import DNTs to TSV (tab separated values, which is similar to CSV but uses tabs), with some augmentations (comments, a Visual Studio Code extension that added some useful information, and basic error checking); later I've expanded the system to add automated testing to catch common developer mistakes and prevent certain types of problems from happening.
Going into detail about that whole process deserves its own tech blog post, so I'll just tl;dr and say that by moving to a git and text based workflow for our most common point of conflict dramatically reduced problems and increased our productivity. We can also review what changes we have pending for the next patch, inspect the changes, and catch issues ahead of time.
The system even takes care of building a common package that is posted to Discord so that we don't have to rely on any individual dev to create the package.
That being said, at that point we're still in the business of some poor dev having to remote desktop and upload files. They had to upload all the loose resource files (actions, visuals, etc) to the test server, upload the DNT CI/CD package, run the time machine script, and restart the game server. We avoided conflicts on those files by constantly uploading resource packages to another Discord channel and noting what changes we made to what files. For the most part, this worked well and that's how Duck development ran for a very long time.
The big push
As with most improvements that tend to happen in the developer side of Project Duck, the most recent improvements came out of my personal frustration.
While working on the 2020 Spooktacular event, we enlisted everyone's favorite toucan Gekkouga to work on assassins - he's been helping out here and there for a long time as a tester and dev helper, but this was his first "big" contribution file-wise.
Adding direct access to the test server is a security risk (since there's only one account that must be shared between people with access) so we've kept the number of people with access as low as possible (Altair, Roy, myself, Joorji, Kozima - the core devs), so poor birb had to constantly upload files to Discord and ask for deployments to do tests. Sometimes we'd miss his message and his change wouldn't make it in, and he'd have to wait for the next deployment. This obviously really sucks (I also lost count of how many files I threw at Joorji).
The obvious answer that many of you reading at this point are probably thinking is to set up some sort of shared folder, and that's what we did. I set up a shared folder (we call it "Staging") and user accounts for each developer on the test server, chroot jailed them to that shared folder (so basically, when they connect to the shared folder, they can only access files in that folder and not outside), and set up a few scripts to make deployments easier. Now, all we had to do was sync the remote folder to our local working folder (using WinSCP's sync feature, so yes we're using SFTP) and coordinate what files we were editing to avoid conflicts.
Now, we only needed a privileged dev to perform the deployment itself, in which case the scripts made that easy:
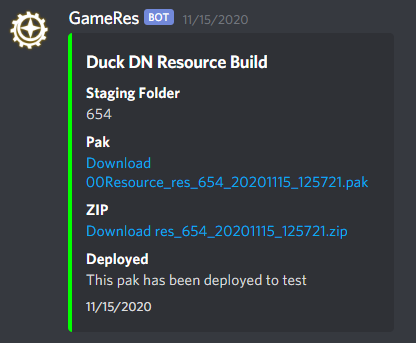
- First, run a script that asked you what folder within Staging to package; it took that folder, generated the mod pak, zipped the files, uploaded them to our developer CDN, posted links to those into Discord, and copied the files to the test server resource folder (for the game server to load)
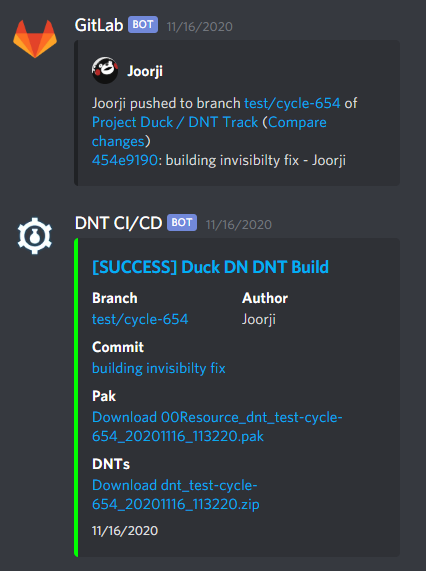
- Next, run a script that asked you for a DNT CI/CD link; it downloaded the DNT package, extracted it to the test server resource folder, and posted a message
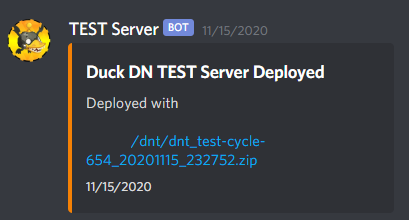
- Finally, run a script that restarted the game server
Now we only needed a dev to hop on to run a few scripts and then hop off - because the resource files were already on the same machine, we avoided the slow process of uploading files from our local computers. We also now have a single source of truth for our files and the resource build means we have a copy of the files at every test deployment, so we can also selectively back out changes as we go.
Self-service best service
This system is all fine and dandy but we still have to remote desktop to the test server to deploy, which still bottlenecks on that short list of people (and its also a pain in the butt). We can do better! I got annoyed again!
Enter WahrBot.
WahrBot is my personal Discord bot that many DN players are familiar with - it provides basic Discord management features, some DN reference material (.dn fd 100% anyone?), random "fun" commands, music bot, and some custom features for certain servers and people.
Since we'd been using Discord to post links and status updates to our developer channels, logically we should be able to manage the test server from Discord - like running those convenient scripts without actually having to remote desktop to the server.
"But Vahr, your bot runs on some random ass Linux server on Linode, but test server is a Windows server on OVH!"
Since WahrBot doesn't run where we need it to run, I could either set up another instance on test server, or set up an agent that acts on behalf of WahrBot. I chose the latter, since running a customized version of WahrBot is a lot of extra work to maintain, and while it has a module system, just having to keep one bot updated with Discord's constant changes is enough pain already.
The test server runs an agent that exposes a set of endpoints over HTTP - hit a specific endpoint with the parameters you want, and the agent will execute that action. Pretty straightforward (after you consider security and all that, but I'll just handwave over that - it essentially boils down to having a secret password). While I could have had the agent just run the script files directly, I did want to practice my Rust programming skills (the agent is written in Rust, using Rocket as the HTTP server library), and so I ported the (PowerShell) scripts to Rust in the agent itself, which does make it easier to report issues when they do happen and nailed a bit of a performance improvement too.
The changes to WahrBot, on the other hand, are a little more involved. We still have three tasks:
Package and Deploy Resources
For this, I opted to use a command, since there's no obvious launch surface or interactable "thing" to start from:
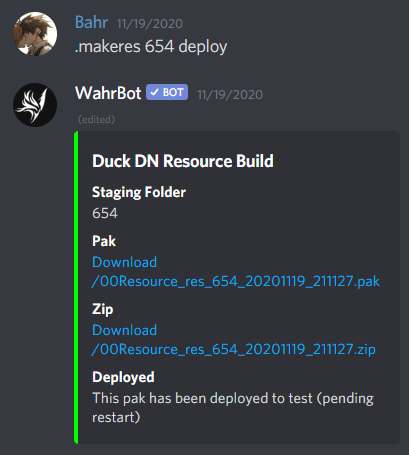
Behind the scenes, the bot receives the command, verifies that it was issued by a developer (WahrBot has an extensive (but invisible) permissioning system; all the developers who can use this command have a specific "grant" attached to them), posts a message (color coded yellow with a loading message), and makes an authenticated call to the test server agent, invoking the command with the folder name and whether or not to deploy the files to the game server.
The agent will respond back with details (status, the URLs for the downloads, any errors) and the bot will update the message to its final state - green with details on success (as shown above), or red with the error message.
Deploy DNT-Track
This one's pretty fast and easy - since we already have the DNT pipeline posting builds to the developer channel, we can implement deployments using reactions!
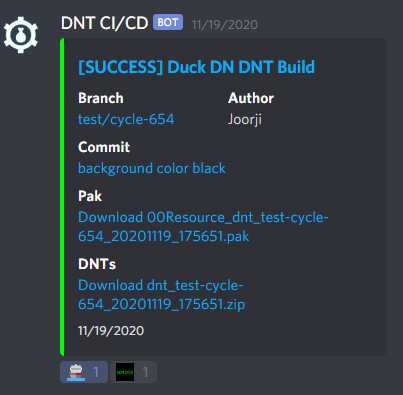
The bot listens for reaction events in the developer channel, and when it sees a boat reaction from an authorized user on a CI/CD message, it extracts the package URL from the message, makes the call to the test agent, and adds a "..." reaction to the message. Once the task is complete, the bot removes its reaction and adds the "Deployed" reaction. In the event of an error, it'll post a followup message with the error.
Restarting Test Server
As with deploying resources, there's no good interaction point here, so this is implemented with a basic command:
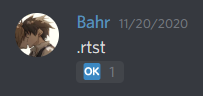
All the usual things happen; in this case after the restart is initiated the agent responds and the bot posts an OK reaction. The restart itself takes a few minutes, so we just assume it's successful.
Future Improvements
Since deploying the new system, we've been super happy with it. We now only ever need to remote access the test server to diagnose issues or resync to prod. Resyncing with prod can probably be added as a feature too, but it happens infrequently enough to where it probably isn't worth the effort.
Also, as mentioned before, we currently aren't able to know when the server is done restarting (we usually just spam login on our clients after 2-3 minutes until it lets us in), so a system that is able to tell when the server is fully up would be useful (for production too, after patches).
Hopefully this was an interesting read and look behind the curtain on how we do things on Duck - in order to make the best experience for you - the players, our developers also need to have the best experience to bring those experiences to life.
I'm usually pretty happy to talk more in detail about things if you ask, so feel free to hit me up in Discord. Thanks again for playing Project Duck! We'll have new content for you to enjoy soon.